
The first feature added to Nautilus as part of my project is support for extracting compressed files. They can be extracted to the current directory or to any other location. The actions are available in the context menu:
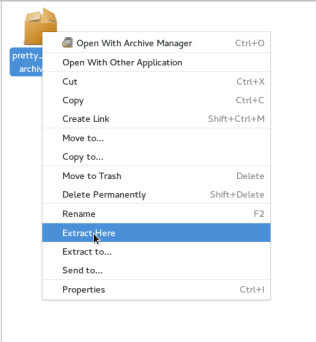 Now you might be wondering, why add these to Nautilus if they look exactly the same as file-roller’s extension? Well, handling extraction internally comes with a few changes:
Now you might be wondering, why add these to Nautilus if they look exactly the same as file-roller’s extension? Well, handling extraction internally comes with a few changes:
- improved progress feedback, integrated into the system used by the rest of the operations
- fine-grained control over the operation, including conflict situations which are now handled using Nautilus’ dialogs
- and probably, the most important change, extracting files in a way that avoids cluttering the user’s workspace. No matter what the archive’s contents are, they will always be placed in a single file or top-level folder – I’ll elaborate on that in a moment.
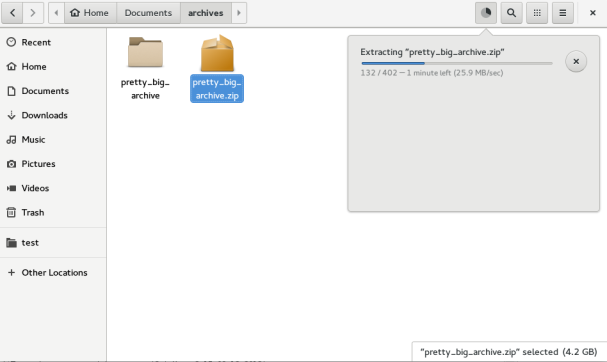
As I mentioned in my first post, the goal of this project is to simplify working with archives, and creating just one top-level item as a result of an extraction really reduces complexity. It is done in a pretty simple way:
- if the archive has a root element and they have the same base names (like image.zip which contains image.png or a folder named image/), the root element is extracted as it is
- if the root element has a different name or the archive has multiple elements, they are extracted in a folder having the same name as the archive, without its extension
As a result, the output will always have the name of the source archive, making it easy to find after an extraction. Also, the maximum number of conflicts an extraction can have is just one, the output itself. Hurray, no more need to go through a thousand dialogs!
If you have any suggestion or idea on how to improve this operation, feel free to drop a comment with it! Feedback is also much appreciated 🙂 See you in the next one!

I like the one top-level item as output, as more than once I got multiple files merged in the current folder and that’s really frustrating. The progress feedback looks good, though I would have expected extensions to be able to do that so FileRoller itself or any other extension could make use of it (maybe the API does allow for it, hope so).
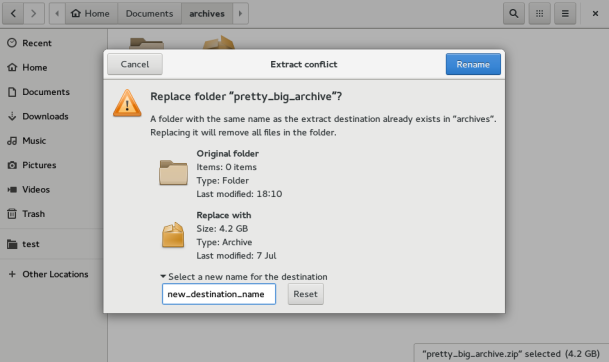
Now what looks scary is the Extract conflic window. Maybe that’s a mockup or it’s not the final implementation.. I would never expect it to “remove all files” in the destination folder under any circumstance. I think that, at the very least, the window should give the option to merge the files, besides renaming the folder. With the current wording I would guess that leaving the same name would delete the current files.. actually I think even clicking Cancel would do that, as I’m canceling the renaming, or is it the entire extract process? I’m not a native English speaker so I may be getting it wrong, but it looks confusing to me
LikeLike
Hey, to address the issues you mentioned:
– we decided to allow only renaming and destination replacing as most of the times the existing destination will be the result of a previous extraction of the same archive. In this way we also reduce the conflicts number down to a maximum of one
– leaving the same name would indeed delete the current files
– the “Cancel” button would cancel the entire extract operation
LikeLike
So suppose you installed an application locally, let’s say in “/home/user/some_application/”, and a few months later there is an update of that application in the form of a binary patch zip-archive.
Currently you would extract it to “/home/user/some_application/”, with the expectation that the patch will be merged with the original application.
But with the new method this will not work any more, and requires to first extract with rename, and then manually merge the extracted patch with the original application, if I understand correctly?
LikeLike
@Elias,
Both “Extract here” and “Extract to” work in such a way that only one item will be created in the destination (current folder for “Extract here” or the one picked from the file chooser for “Extract to”). So yeah, for “Extract to” the items in the archive will not just be dumped / merged in the destination. In this situation you would have to manually merge the archive output with the existing app. This could still be done with about the same amount of actions – “Extract here”, open extracted folder, move files to app folder (and then maybe remove the extracted stuff and the archive).
When it was discussed whether to handle merges or not, we agreed that reducing conflicts and cluttering of extract destinations has more benefits. What do you think?
LikeLike
@razvanchitu,
Yes, you’re right, reducing conflicts and cluttering of extract destinations has more benefits.
BTW, binary patch zip-archives are rather a Windows/closed source thing, this is a very rare use case on Linux.
LikeLike
Looking good.
I think it would be nice to have the Extract here and Extract to items higher up the context menu — under Open with. I think their current location is too easy to miss.
LikeLike
Thanks! I put the two menu items in the extensions section where the ones from the file-roller extension would usually be. I guess they could be moved in the upper part of the menu. I will ask in #gnome-design, see what they think too.
LikeLike
So this is a bit like dtrx but in nautilus now? Is there no way this could have been done using an API, that other programmes can hook into? Is it easy to support new archive formats ?
LikeLike
I agree. This seems as though literally everything that was mentioned as goals could be achieved via a separate (reusable) service that communicates with nautilus via dbus.
LikeLike
We are using a separate tool for the actual extraction / compression operations. The work in Nautilus is to plug it in along the other operations. Right now the tool is just a library that offers this functionality. Do you think it should be a separate process?
LikeLike
Possibly. A goal, imho, should be to offer a core set of “safe” (namespaced) services from which any application can make requests.
It could be a daemon, like print, or reside within an extant process like the old webview.
A daemon is typically cleaner, and safer, and it would map to this kind of functionality nicely.
Again, the important things, to me, are that extraction is done safely, and that any process can request the use of the service over dbus.
Best
Liam
LikeLike
Oh, just saw your original post where you answer some of my questions already 🙂
LikeLike
Heh, no problem. Nautilus handles compressed files using a tool built around libarchive, so we would have to ask them to add support for new archive formats (or maybe add them ourselves!).
LikeLike
It feels a bit weird / inconsistent to have different options for file extraction versus file move/copy operations. I think I’d prefer to have the exact same pop-up & resolution options in both cases.
Other than that, this is a great improvement over the current non-integrated file-roller. Looking forward!
LikeLike
I’d prefer if there was a single “Extract to…” menu entry right beneath “Copy to…” that would default to the current directory.
LikeLike
More discussion about this subject here: http://www.omgubuntu.co.uk/2016/07/native-nautilus-file-extract-archive
LikeLike
Re: the binary-patches being a windows thing. I do have windows VMs, and often do “windows things” using linux, and am probably not unusual in that respect.
LikeLike