
With extraction support in Nautilus, the next feature that I’ve implemented as part of my project is automatic decompression. While the name is a bit fancy, this feature is just about extracting archives instead of opening them in an archive manager. From the UI perspective, this only means a little change in the context menu:

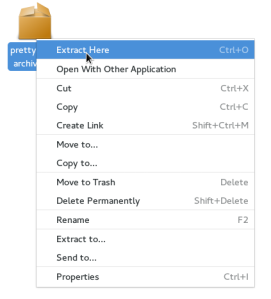
Notice that only the “Open With <default_application>” menu item gets replaced. Archives can still be opened in other applications
Now why would you want to do this? The reason behind is to reduce working with files in a compressed format. Instead of opening the archive in a different application to take out some files, you can extract it all from the start and then interact with the files straight away from the file manager. Once the files are on your system, you can do anything that you could have done from an archive manager and more. For example, if you only wanted to extract a few files, you can just remove the rest.
One could argue that extracting an archive could take way longer than just opening it in an archive manager. While this can be true for very large compressed files, most of the times the process takes only a few seconds – about the same time it takes to open a different application. Moreover, if you just want to open a file inside the archive manager, the manager will first extract it to your disk anyway.
This might be a minor change in terms of code and added functionality, but it is quite important when it comes to how we interact with compressed files. For users that are not fond of it, we decided on adding a preference for disabling automatic decompression.

That’s pretty much it for extraction in Nautilus. Right now I’m polishing compression, so I’ll see you in my next post where I talk about it! As always, feedback, suggestions and ideas are much appreciated 🙂

I’ve littered my Downloads directory before by accidentally extracting an archive into it that had a lot of items at root level. To make things worse it also preserved the mtimes from the archive, making separating the files difficult. I do not remember if Nautilus was the extractor, though.
How about a) never preserving mtimes and b) extracting into a subdir if the archive contains more than three root items?
LikeLike
Littering the extraction destination is no longer an issue considering how the operation is done by Nautilus. Only one top-level item will be created when extracting:
– if the archive has a root element that is named the same as the archive (except extensions), extract it
– if the root element is not named like the archive or the archive has multiple root elements, create a directory named like the archive and extract the stuff there
In this way, the output will always have the same name as the archive, so you can locate it pretty quickly. Also, if the operation was a mistake, it will be easy to clean up.
If you want to read more about extraction in Nautilus check out my previous post where I went a bit more into detail: https://razvanchitu.wordpress.com/2016/07/14/extraction-support-in-nautilus/
LikeLike
Ah, this is very nice. Thanks.
LikeLike
That such a nice work. Congratulations!
LikeLike
Thanks a lot!
LikeLike
What about archives on remote locations (a sub share)? I don’t want to bother my colleges to see the decompressed files. Furthermore the network drive is replicated and the decompressed files will immediately cause traffic to for the extracted files. Also performance will be an issue: it’s usually faster to copy to a local location and then decompress it. But I usually peek before I copy it.
Last but not least: what about read-only locations?
LikeLike
For read-only locations the solution will be to have “Extract to” the default option. We haven’t discussed about remote locations, but I suppose “Extract to” would work here too. Maybe we could configure the file-chooser dialog prompted by “Extract to” to show up with a destination on the user’s system. What do you think?
LikeLike
Extract-to sounds great. Would the archive be copied to a local temp beforehand?
LikeLike
Hmm, I don’t know but if I were to guess I’d say no. It really depends on how the gvfs backend behind handles reading and seeking, because that is what the extraction tool uses.
LikeLike
OK, still sounds reasonable. I think thresholds are not required, and would depend on your location (VPN/local network) which would result in too many frustrating configuration options.
Enjoyed the discussion, thanks for your efforts!
LikeLike
There could be a threshold, say 100Mb? Where the recommended option would be opening the external application rather than uncompress right away…
Great work!!
LikeLike
It takes about the same time to extract 100Mb that it takes to open an archive manager. We strongly encourage users to *not* work with files in a compressed format. In this way they can interact with them transparently. Adding a size limit would kinda defeat the purpose.
LikeLike
hm. But it is an issue for large archives. How do you deal with 42.zip http://www.unforgettable.dk/42.zip ?
LikeLike
Nautilus will not decompress recursively. It would require the user to extract the nested zips as well, if he’s got the patience.
LikeLike
Actually I like idea to open an archive as a folder. It must mount (extract) to temp directory to cache.
LikeLike
What we want to achieve with automatic decompression is to *convert* an archive to a folder, so users can interact with the files inside like they would with any other file on the system. Opening an archive as a folder has benefits, but hides a lot of things from the user. For example, if a user would want to “Paste” an empty file into a .zip archive opened as a folder, it could take up to minutes if the archive is huge, because it has to be recreated. On the other hand, if the archive would be extracted to a folder, pasting the file would be instantaneous, as expected.
LikeLike
Right! Pasting can be done as well as other operations with progress status. Aren’t you going to implement that feature within this GSoC?
LikeLike
I am indeed going to be working on it, but it will probably not be a part of this release. I might not have been clear in my posts but right now we really want to minimize working with files in a compressed format.
If you are interested about opening archives from Nautilus, you could try the existing gvfs backend for archives. It “mounts” an archive and so it can be accessed from Nautilus as a read-only folder. The plan is to investigate whether / how we can add write support to this gvfs backend. But even so, I don’t think we could pretend an archive is a folder while it is still in compressed format, because operations will not be done in the same way (see the paste issue I mentioned).
LikeLike
Cool. It sounds very promising to me! I had the same idea about gvfs in my mind year ago. About pasting: you can add Archive Operation in this case to indicate recompressing. Keep rocking!
LikeLike
Cooll! Yeah, maybe a detailed progress feedback will work. We’ll see!
LikeLike
I like sane defaults. A user which opens a context menu for an archive in most cases wants to either fully extract the archive or selectively access specific files from the archive (other actions are used less frequently and are still present in the context menu).
Situations to think about what could be made worse with this change might be:
* Archives must always be fully extracted, even for the “only extract N specific files” use-case
* Archives that extract very slowly (sequential access/many files/large size) increase the duration of the use-case completition
* Archives that do not fit on the drives due to not enough space fail for this use-case
* Third-party archive apps can (apparently?) no longer be used as a default app to handle archives easily
Perhaps the “Open With ” item should just be moved below the “Extract here…” and not be removed? I guess that might not work for your goal of “not encouraging users to work with archives” though.
LikeLike
Thanks for the feedback! We did, indeed, consider the cases you mentioned as downsides of having extract as default, but we still think the pros outweigh them. To comment on your points:
– we consider situations when you only need a little fraction of the content inside the archive to happen much less often than the rest.
– even in the case of large files, the process is not extremely slow and chances are that the user will end up extracting the content anyway. Keep in mind that opening a large archive in an archive manager also takes more time, and even more if the user wants to edit things.
– we could offer “Extract to” as default destination and then let the user pick a drive which has space. Alternatively, we could just display an error message saying there is no space and offer the option to open the archive in another application.
– “Open with another application” does essentially the same as “Open with “, as the dialog prompted will have the default app selected and also show you any other archive manager installed.
– you are right, keeping the “Open With” menu item would not really work in this case.
Do you have any suggestion on how to improve our cover of the cases you mentioned?
LikeLike
This is great for most use cases, can we not have ‘browse archive in new window’; or ‘open archive with (default application)’ in the menu? (keeping with other application). Thanks
LikeLike
I love what you’re doing here but I’m not sure I’m a fan of this one yet. Is this going to prompt the user before doing its thing? It would be really surprising behaviour when nothing else in Nautilus behaves like this without prompting. (MacOS does the same, and I find it infuriating. Granted, it isn’t as clever as yours in that it will blindly litter the current directory with hundreds of files from the archive’s root, so you’re at least a step closer to keeping me sane). I also think it’s worth noting that lots of archives have a separate index of files so the archive manager can display those files without decompressing, and plenty of folks use those archive formats for a reason.
There’s a GVFS archive mounting tool (gvfsd-archive). I’m curious if you had considered building something like that, treating an archive as a directory instead of a special file. Is it a lot slower?
Anyway, related feature suggestion: it would be *adorable* if Nautilus selected the extracted file after extracting (assuming the window is in focus and the archive file is still selected).
LikeLike
Hey, thanks! Sorry for a late reply, a health issue kept me away from my computer for a few days. To answer your questions:
– we are not going to prompt the user when he attempts to “open” an archive. Popping up a dialog every time can be more disturbing than the automatic operation itself considering that most archives will be extracted in a few seconds. To make it even more comfortable for the user, we are probably going to select the extracted file, as you suggested 🙂
– we are considering displaying archives as directories and as a matter of fact gvfsd-archive is what we have in mind. The problem with it is that archives will be displayed as read-only mounts. We could add write support to them but the operations will still not be the same – pasting to an archive is not the same as pasting to a folder.
Thanks for the feedback! If you have more suggestions about this (maybe about gvfsd-archive and Nautilus?) please do share them!
LikeLiked by 1 person
Hi, nice work!, regarding compression (and not knowing your plans about it), I just want to let you know (in case you didn’t) that in Nautilus you can already drag files and drop them on any archiver file (zip, tar.gz, etc) and they will be added to the archiver (a file-roller process does the job in the background).
Thanks!
LikeLike
Hello and thanks! Yeah, about the compression thing, Nautilus just invokes “file-roller -a” when files are dragged onto an archive. The problem with this is that in many cases when you add a file to an archive the archive has to be recreated. It would be pretty weird to drag an empty file over a compressed file and see the whole operation take 5 minutes, wouldn’t it? This is why we are going to avoid doing this.
An important goal of this project is to reduce working with archives in order to improve transparency of operations. Rather than having an application secretly recreating the compressed file, why not re-compress the original content with the needed modifications? It might seem a bit more work for the user, but we are trying to offer more information and control over the whole process. What are your thoughts on this?
LikeLike